
This HowTo will take you from a blank/brand new install of Ubuntu 20.04, 22.04, Linux Mint 21 or Zorin OS up to the point where you can run OpenROAD to make a GDS-II file of an RTL design. This HowTo…
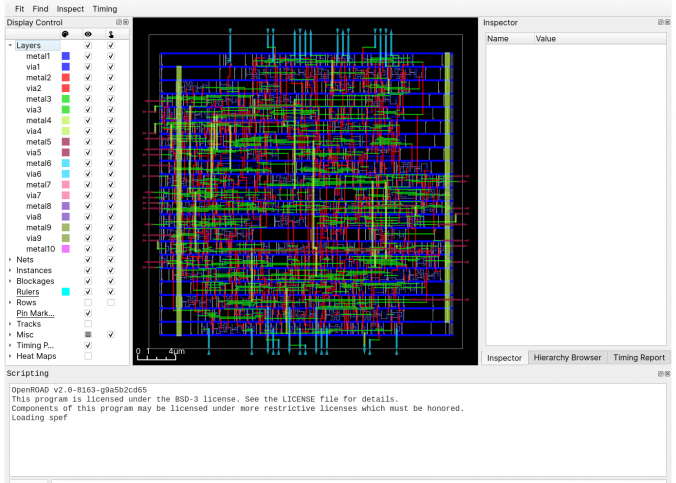
This HowTo will take you from a blank/brand new install of Ubuntu 20.04, 22.04, Linux Mint 21 or Zorin OS up to the point where you can run OpenROAD to make a GDS-II file of an RTL design. This HowTo…
Xilinx put the new version of Vivado up on their website this week.
Most open source tools don’t accept VHDL as an input, which is a real shame/annoyance if VHDL is your thing. What are the options?
This HowTo will take you from a blank/brand new install of Ubuntu 22.04 or Linux Mint 21 up to the point where you can run OpenROAD to make a GDS-II file of a design.
Xilinx put the new version of Vivado up on their website today, with improvement to simulation, timing closure, device support and IP. Read on for details and links.
Here is the slide deck used for the “Trends” presentation:
The International Symposium on FPGAs is scheduled for next week. This article provides links to the proceedings and the papers.
Today, SiFive announced a $1 Billion partnership with Intel, where SiFive will use their flexible customisation platform to support Intel Foundry Services and create Risc-V core that are optimised for Intel’s foundry platforms. SiFive has partnered with IFS to develop…
Vivado 2021.1 came out at the end of last month. What’s new besides the name-change? Read on…
The International Symposium for FPGA 2021 was held last week. If you couldn’t make it to the virtual conference, here’s where to find the papers.